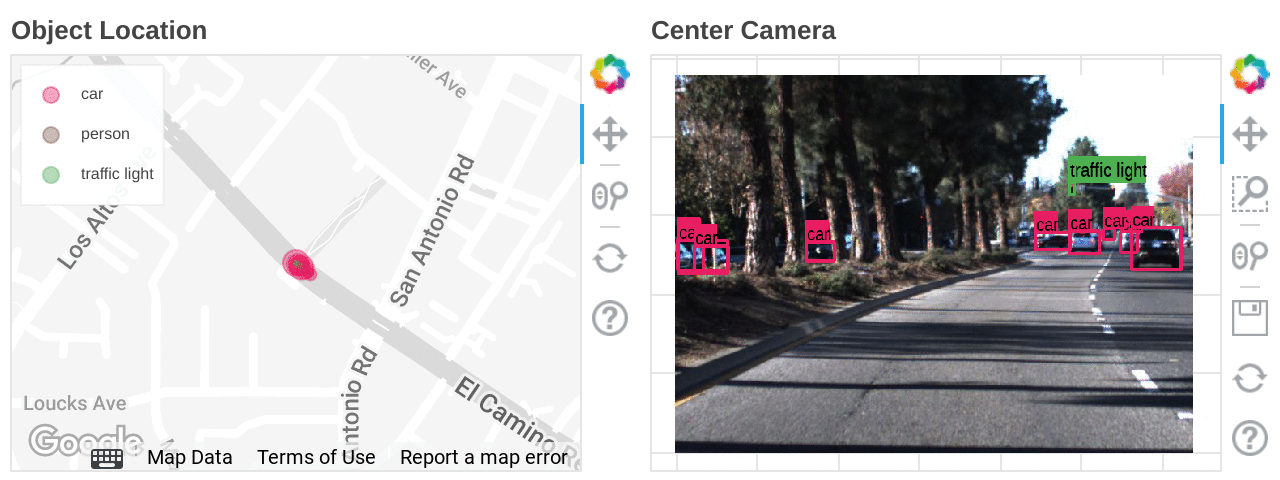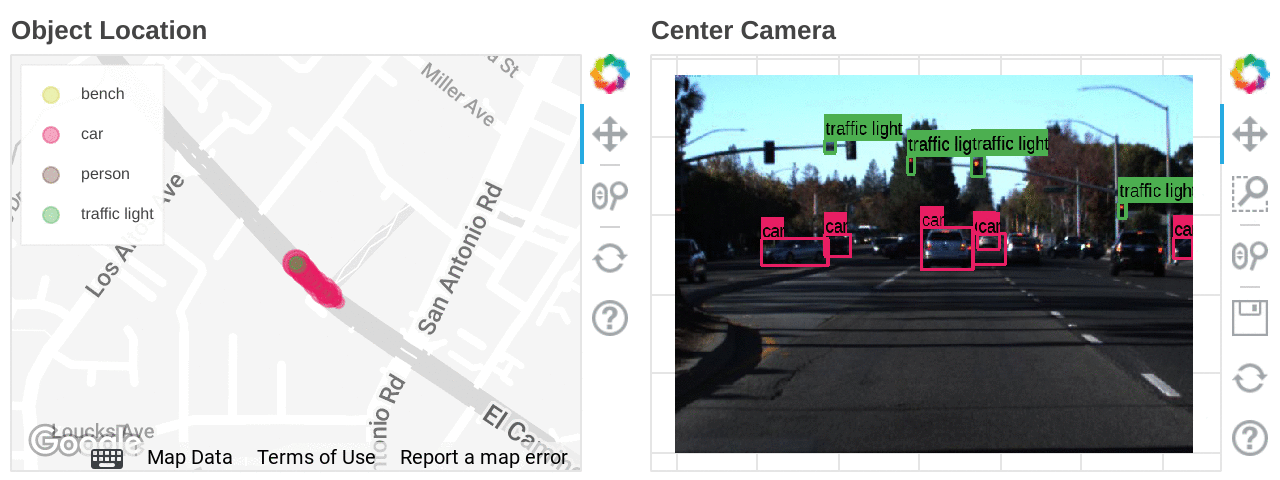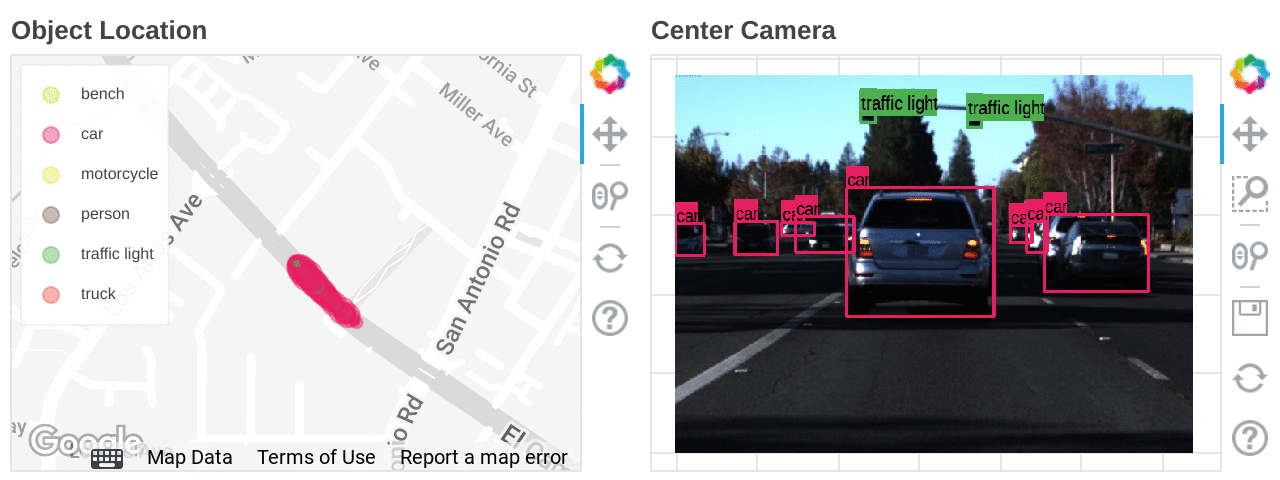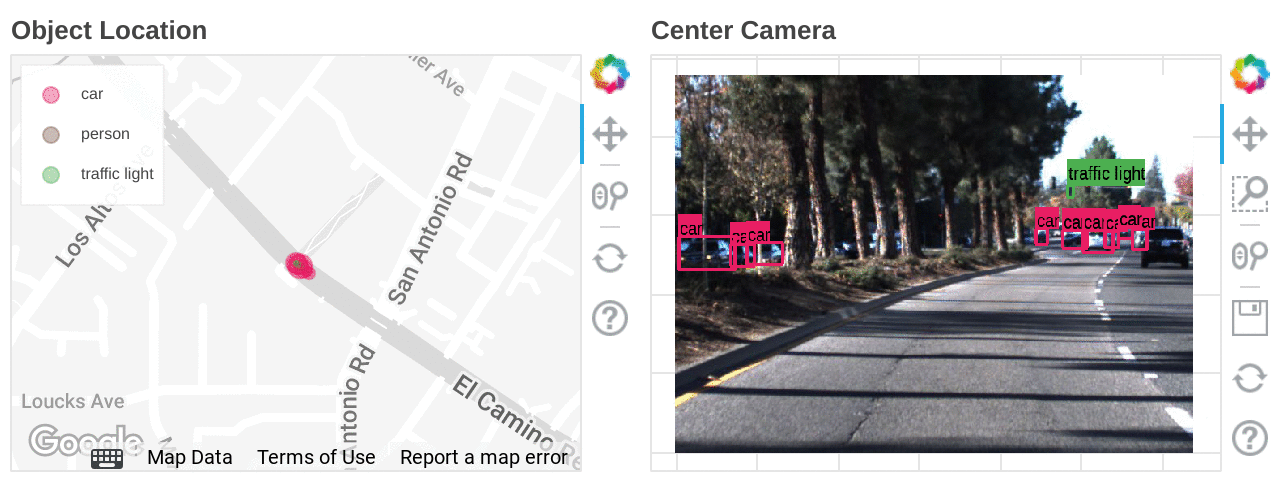
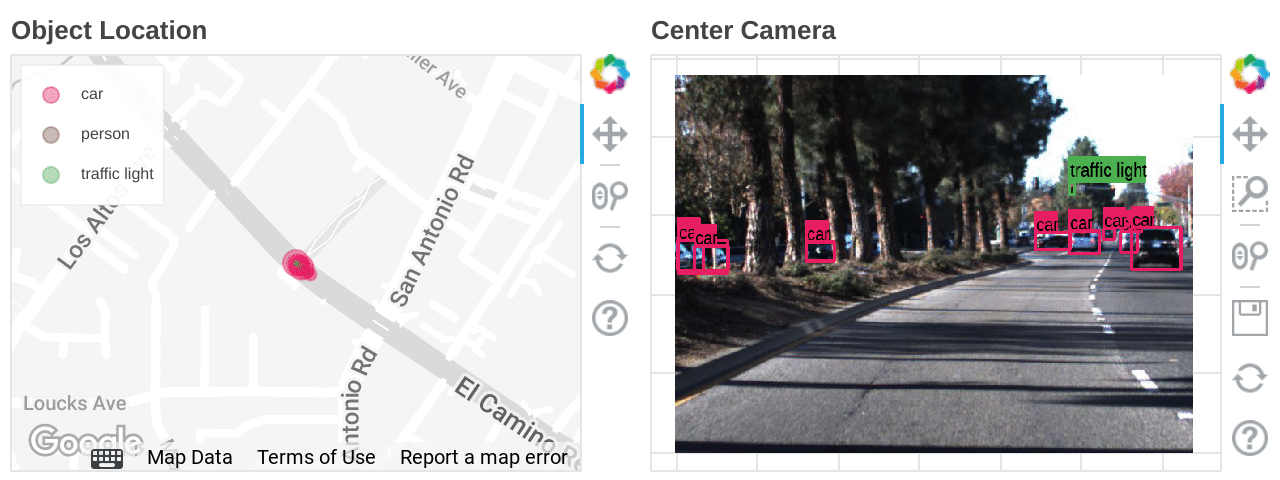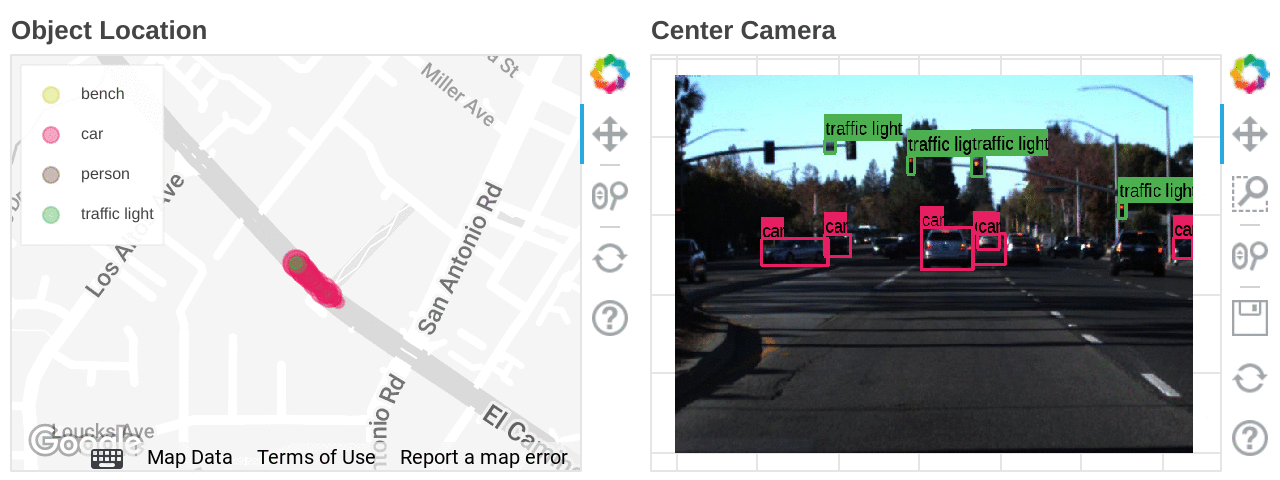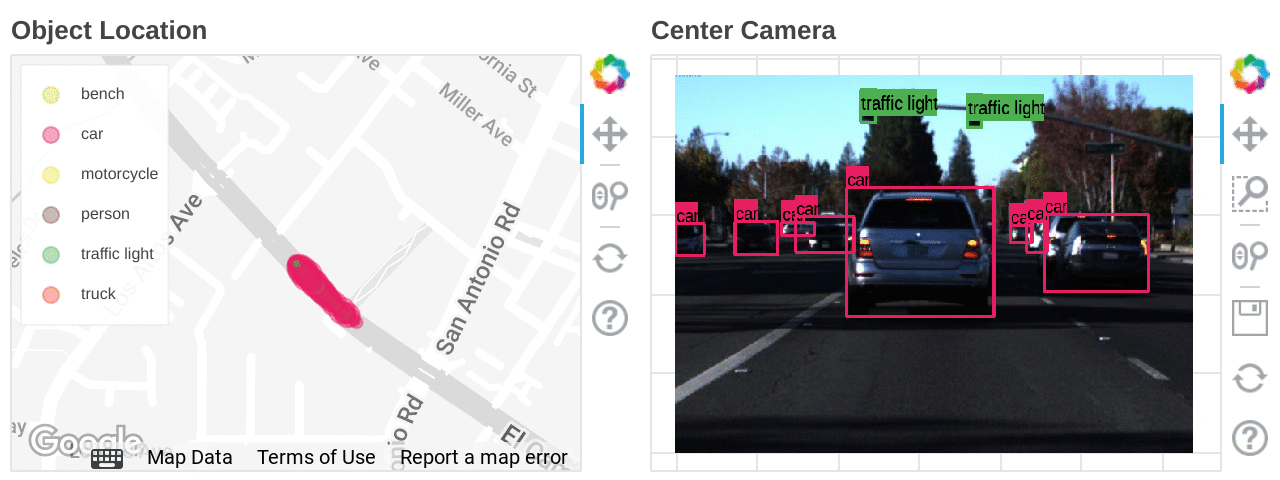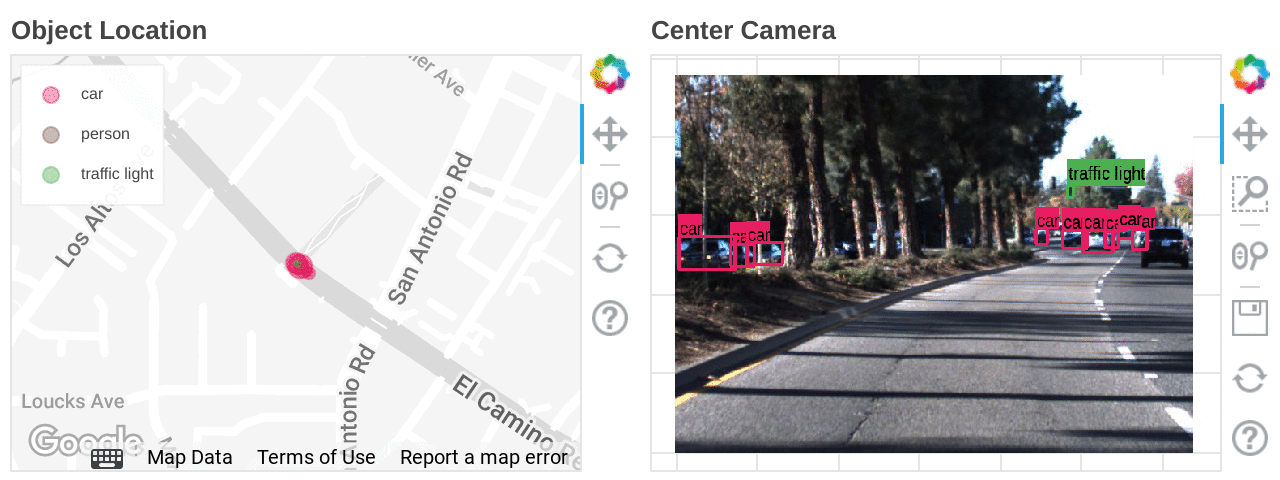
Mapping the types and locations of detected objects
What is Dataflow ML?
Google Cloud Dataflow is a fully managed data processing service that lets users run batch and streaming pipelines on large-scale data in a fast, scalable, and cost-effective manner. Developers can write their pipelines using Apache Beam, which is an open-source, unified programming model that simplifies these large-scale data processing dynamics. Pipelines are expressed with generic transforms that can perform a wide array of operations such as reading and writing from sources and sinks, as well as performing data manipulations such as mapping, windowing, and grouping.
As mentioned in the launch blog for Dataflow ML, we are seeing more enterprises shift to operationalize their artificial intelligence and machine learning capabilities. We wanted to expand use cases of ML/AI for all developers, and as a result, developed a new Beam transform called RunInference.
RunInference lets developers plug in pre-trained models that can be used in production pipelines. The API makes use of core Beam primitives to do the work of productionizing the use of the model, allowing the user to concentrate on model R&D such as modeling training or feature engineering. Coupled with Dataflow’s existing capabilities such as GPU support, users are able to create arbitrarily complex workflow graphs to do pre- and post-processing and build multi-model pipelines.
Building a simple ML pipeline to extract metadata
Now let’s run a Dataflow ML pipeline to process large amounts of data for autonomous driving. If you want to recreate this workflow, please follow the demo code here. As we are using an open-source dataset, we won’t be working with a large data volume. Dataflow automatically scales with your data volume (more specifically, by throughput), so you will not need to modify your pipeline as the data grows 10x or even 1,000x. Dataflow also supports both batch and streaming jobs. In this demo we run a batch job to process saved images. What if we want to process each image uploaded from running vehicles in near real-time? It is easy to convert the pipeline from batch to streaming, by modifying the first transform such as Pub/Sub.
The pipeline shape is shown in the image below. First, it reads the image path from BigQuery, reads the images from Google Cloud Storage, does inference for each image, and then saves the results to BigQuery.
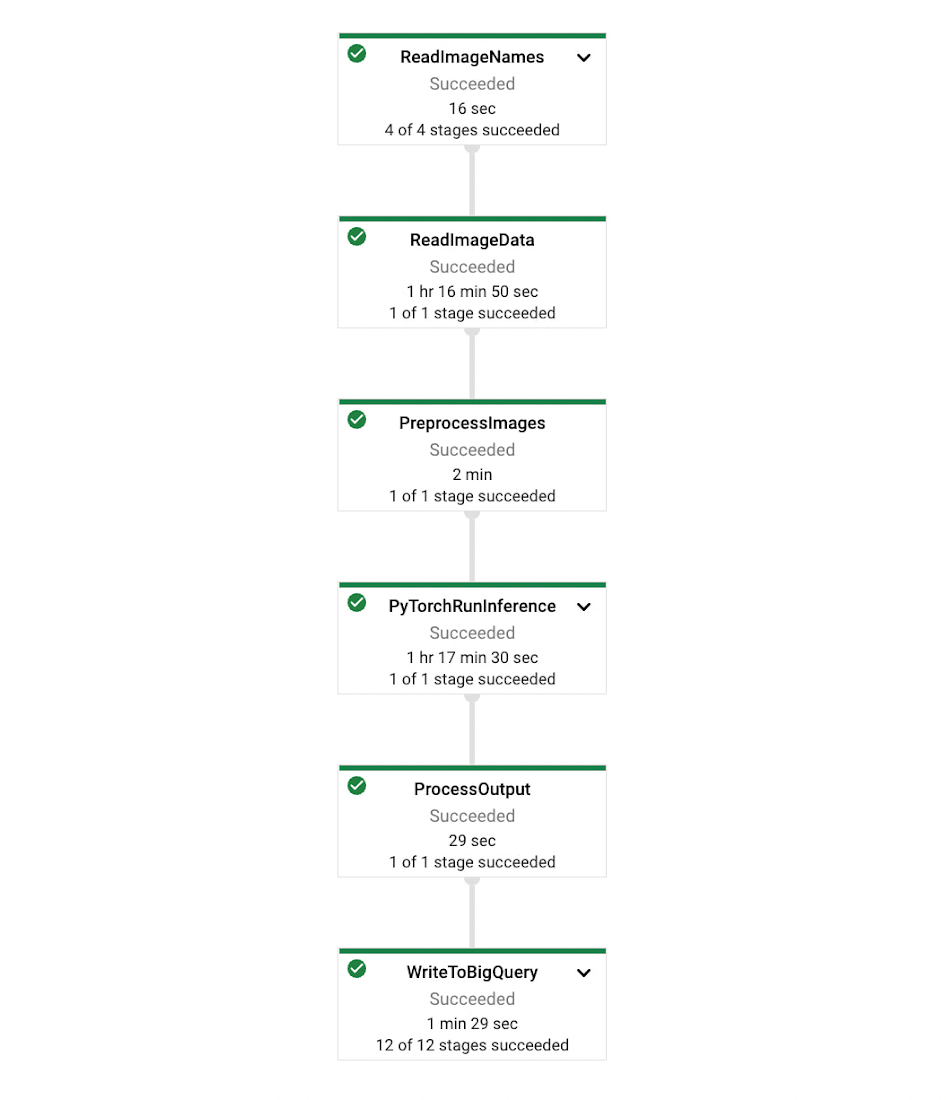
The pipeline to do inference for each image and save the results to BigQuery
Handling ML workloads easily
Using RunInference
Writing a Beam pipeline using RunInference looks like this:
from apache_beam.ml.inference.base import RunInference
with pipeline as p:
predictions = ( p | 'Read' >> beam.ReadFromSource('a_source')
| 'RunInference' >> RunInference(<model_handler>))
from apache_beam.ml.inference.sklearn_inference import SklearnModelHandlerNumpy
from apache_beam.ml.inference.pytorch_inference import PytorchModelHandlerTensor
Batching in RunInference
As seen in the code of this demo pipeline, we configured the ModelHandler’s batch_elements_kwargs function. Why did we do this? RunInference uses dynamic batching via the BatchElements transform, which batches elements for amortized processing by profiling the time taken by downstream operations. The API, however, cannot batch elements of different shapes, so samples passed to the transform must be of the same dimension or length.

The BatchElements transform can be seen in the graph view, inside PyTorchRunInference transform
class PytorchNoBatchModelHandler(PytorchModelHandlerKeyedTensor):
def batch_elements_kwargs(self):
return {'min_batch_size':10, 'max_batch_size':10}
What’s Next
We ran an object detection model in Dataflow ML to search for images under specific conditions. Object detection can only detect classes that the model has learned, so if you want even more flexibility in exploring the scene, you can use the feature extraction model to create indexes for the Vertex AI Matching Engine. Vertex AI Matching Engine can search data with similar features with latency as low as 5ms in the 50th percentile.
Also, if latitude and longitude information is included in the dataset, you can accelerate data analysis by combining BigQuery GIS and BI tools such as Looker.
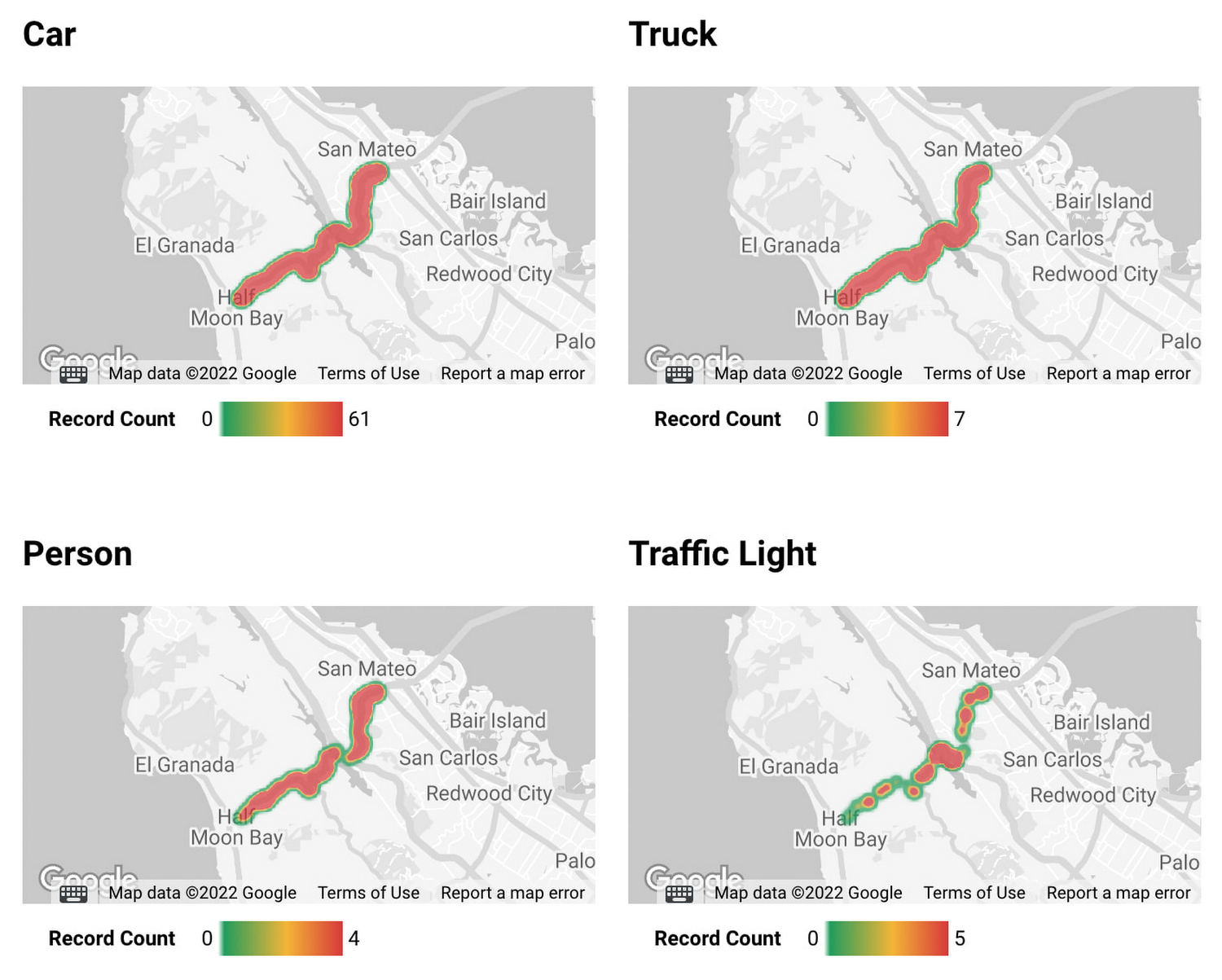
Location heat mapping for each detected object built on Looker Studio
Additional readings
- Read more about the RunInference Beam transform on the Apache Beam website.
- Watch this talk about RunInference at Beam Summit 2022.
- Read this blog post on how to use TensorFlow models in a pipeline.
- Read the example pipelines using RunInference that do tasks such as object detection and language modeling.
By Andy Ye, Software Engineer, Dataflow ML | Hayato Yoshikawa, Customer Engineer, Automotive
Source Google Cloud



